ADDRESS
Khurrampur, Farrukh Nagar, Haily Mandi Road, Gurgaon, Delhi (NCR), 122506
Computer Vision
Computer vision is a field of computer science that focuses on enabling computers to identify and understand objects and people in images and videos. Like other types of AI, computer vision seeks to perform and automate tasks that replicate human capabilities. In this case, computer vision seeks to replicate both the way humans see, and the way humans make sense of what they see.
The range of practical applications for computer vision technology makes it a central component of many modern innovations and solutions. Computer vision can be run in the cloud or on premises.
Computer vision is a field of artificial intelligence (AI) that enables computers and systems to derive meaningful information from digital images, videos and other visual inputs — and take actions or make recommendations based on that information. If AI enables computers to think, computer vision enables them to see, observe and understand.
Computer vision works much the same as human vision, except humans have a head start. Human sight has the advantage of lifetimes of context to train how to tell objects apart, how far away they are, whether they are moving and whether there is something wrong in an image.

As humans, we generally spend our lives observing our surroundings using optic nerves, retinas, and the visual cortex. We gain context to differentiate between objects, gauge their distance from us and other objects, calculate their movement speed, and spot mistakes. Similarly, computer vision enables AI-powered machines to train themselves to carry out these very processes. These machines use a combination of cameras, algorithms, and data to do so.
However, unlike humans, computers do not get tired. You can train machines powered by computer vision to analyze thousands of production assets or products in minutes. This allows production plants to automate the detection of defects indiscernible to the human eye.
Computer vision needs a large database to be truly effective. This is because these solutions analyze information repeatedly until they gain every possible insight required for their assigned task. For instance, a computer trained to recognize healthy crops would need to ‘see’ thousands of visual reference inputs of crops, farmland, animals, and other related objects. Only then would it effectively recognize different types of healthy crops, differentiate them from unhealthy crops, gauge farmland quality, detect pests and other animals among the crops, and so on.
· A sensing device captures an image. The sensing device is often just a camera, but could be a video camera, medical imaging device, or any other type of device that captures an image for analysis.
· The image is then sent to an interpreting device. The interpreting device uses pattern recognition to break the image down, compare the patterns in the image against its library of known patterns, and determine if any of the content in the image is a match. The pattern could be something general, like the appearance of a certain type of object, or it could be based on unique identifiers such as facial features.
· A user requests specific information about an image, and the interpreting device provides the information requested based on its analysis of the image.
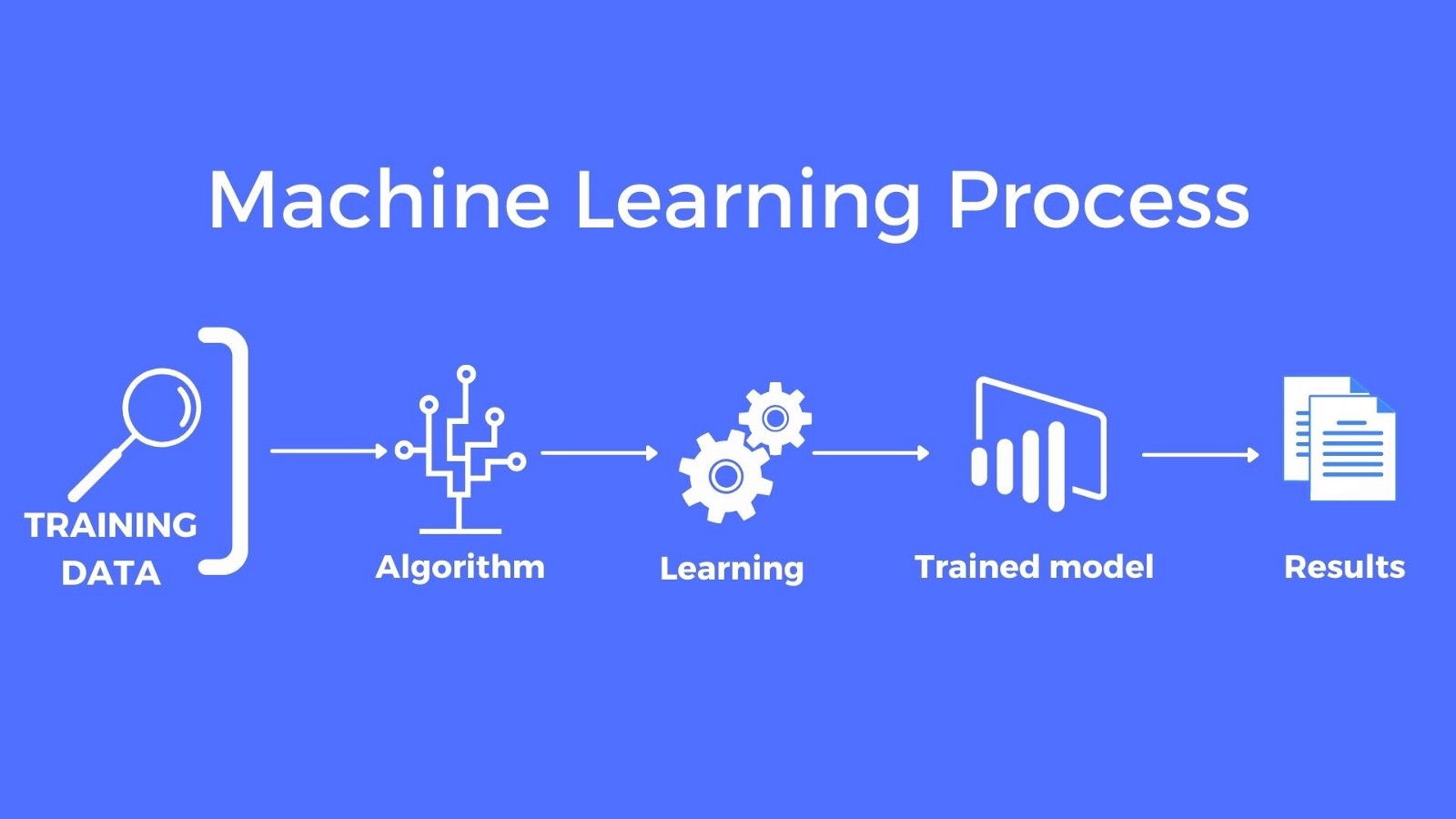
· Modern computer vision applications are shifting away from statistical methods for analyzing images and increasingly relying on what is known as deep learning. With deep learning, a computer vision application runs on a type of algorithm called a neural network, which allows it deliver even more accurate analyses of images. In addition, deep learning allows a computer vision program to retain the information from each image it analyzes—so it gets more and more accurate the more it is used.
In 2015, technology leader Google rolled out its instant translation service that leverages computer vision through smartphone cameras. Neural Machine Translation, a key system that drives instantaneous and accurate computer vision-based translation, was incorporated into Google Translate web results in 2016.
When the app is opened on internet-enabled devices with cameras, the cameras detect any text in the real world. The app then automatically detects the text and translates it into the language of the user’s choice. For instance, a person can point their camera at a billboard or poster that has text in another language and read what it says in the language of their choice on their smartphone screen.
Apart from Translate, Google also uses computer vision in its Lens service. Both services are capable of instantly translating over 100 languages. Google’s translation services are already benefiting users across Asia, Africa, and Europe, with numerous languages concentrated in relatively small geographic areas.
Not to be left behind, technology giant Meta (earlier known as Facebook) is also dabbling in computer vision for various exciting applications. One such use is the conversion of 2D pictures into 3D models.
Launched in 2018, Facebook 3D Photo originally required a smartphone with dual cameras to generate 3D images and create a depth map. While this originally limited the popularity of this feature, the widespread availability of economically priced dual-camera phones has since increased the use of this computer vision-powered feature.
3D Photo turns ordinary two-dimensional photographs into 3D images. Users can rotate, tilt, or scroll on their smartphones to view these pictures from different perspectives. Machine learning is used for the extrapolation of the 3D shape of the objects depicted in the image. Through this process, a realistic-looking 3D effect is applied to the picture.
Advances in computer vision algorithms used by Meta have enabled the 3D Photo feature to be applied to any image. Today, one can use mid-range Android or iOS phones to turn decades-old pictures into 3D, making this feature popular among Facebook users.
Meta is not the only company exploring the application of computer vision in 2D-to-3D image conversion. Google-backed DeepMind and GPU market leader Nvidia are both experimenting with AI systems that allow computers to perceive pictures from varying angles, similar to how humans do.
YOLO, which stands for You Only Look Once, is a pre-trained object detection model that leverages transfer learning. You can use it for numerous applications, including enforcing social distancing guidelines.
As a computer vision solution, the YOLO algorithm can detect and recognize objects in a visual input in real-time. This is achieved using convolutional neural networks that can predict different bounding boxes and class probabilities simultaneously.
As its name implies, YOLO can detect objects by passing an image through a neural network only once. The algorithm completes the prediction for an entire image within one algorithm run. It is also capable of ‘learning’ new things quickly and effectively, storing data on object representations and leveraging this information for object detection.
Faceapp is a popular image manipulation application that modifies visual inputs of human faces to change gender, age, and other features. This is achieved through deep convolutional generative adversarial networks, a specific subtype of computer vision.
Faceapp combines image recognition principles, a key aspect of facial recognition, with deep learning to recognize key facial features such as cheekbones, eyelids, nose bridge, and jawline. Once these features are outlined on the human face, the app can modify them to transform the image.
Faceapp works by collecting sample data from the smartphones of multiple users and feeding it to the deep neural networks. This allows the system to ‘learn’ every small detail of the appearance of the human face. These learnings are then used to bolster the app’s predictive ability and enable it to simulate wrinkles, modify hairlines, and make other realistic changes to images of the human face.
SentioScope is a fitness and sports tracking system developed by Sentio. It primarily operates as a player tracking solution for soccer, processing real-time visual inputs from live games. Recorded data is uploaded to cloud-based analytical platforms.
SentioScope relies on a 4K camera setup to capture visual inputs. It then processes these inputs to detect players and gain real-time insights from their movement and behavior.
This computer vision-powered solution creates a conceptual model of the soccer field, representing the game in a two-dimensional world. This 2D model is partitioned into a grid of dense spatial cells. Each cell represents a unique ground point on the field, shown as a fixed image patch in the video.
SentioScope is powered by machine learning and trained with more than 100,000 player samples. This enables it to detect ‘player’ cells in the footage of soccer games. The probabilistic algorithm can function in numerous types of challenging visibility conditions.
Date : 07 Oct, 2023

Computer Vision